本系列文章会介绍两个 Android NDK Demo,拉流端会实现一个基于 FFmpeg 的视频播放器 Demo,推流端会实现一个视频直播 Demo,当然在做 Demo 之前会介绍音视频的基础知识。以下是本系列文章的目录:
Android 音视频基础知识
Android 音视频播放器 Demo(一)—— 视频解码与渲染
Android 音视频播放器 Demo(二)—— 音频解码与音视频同步
RTMP 直播推流 Demo(一)—— 项目配置与视频预览
RTMP 直播推流 Demo(二)—— 音频推流与视频推流
Demo 仅供 NDK 初学者参考之用,大神请避坑~
视频直播推流主要利用了音视频编码,而视频播放器主要利用了音视频解码,因此我们要对音视频编解码的基础知识有一定的了解。
1、颜色编码系统
颜色编码系统是一种将颜色与数字或字符进行对应的系统,常用于计算机图形处理、网页设计、印刷等领域。以下是几种常见的颜色编码系统:
- RGB(红绿蓝):RGB是最常见的颜色编码系统之一。它使用红色(R)、绿色(G)和蓝色(B)三个通道的数值来表示颜色。每个通道的取值范围是 0 到 255,表示从无色到全色的强度。例如,纯红色可以表示为 RGB(255, 0, 0)
- HEX(十六进制):HEX 是在 Web 设计中广泛使用的颜色编码系统。它使用 6 位十六进制数来表示颜色,前两位表示红色通道,中间两位表示绿色通道,最后两位表示蓝色通道。每个通道的取值范围是 00 到 FF。例如,纯红色可以表示为 #FF0000
- CMYK(青、洋红、黄、黑):CMYK 是一种用于印刷颜色的编码系统。它使用青色(Cyan)、洋红色(Magenta)、黄色(Yellow)和黑色(Key)四个颜色通道的百分比或数值来表示颜色。CMYK 编码系统是基于颜料的混色原理,与 RGB 编码系统不同。例如,纯红色可以表示为 CMYK(0, 100, 100, 0)。
- HSL(色相、饱和度、亮度):HSL 是一种将颜色表示为色相(Hue)、饱和度(Saturation)和亮度(Lightness)三个属性的编码系统。色相表示颜色在色轮上的位置,取值范围是 0 到 360 度。饱和度表示颜色的纯度或灰度,取值范围是 0 到 100%。亮度表示颜色的明暗程度,取值范围也是 0 到 100%。例如,纯红色可以表示为 HSL(0, 100%, 50%)
- YUV(亮度、色度、色度):亮度(Y)表示图像的明亮程度,取值范围通常是 0 到 255。色度(U、V)表示图像的颜色信息。色度分量以差值的方式表示颜色与亮度的偏差。U 分量表示蓝色偏差,V 分量表示红色偏差。U 和 V 的取值范围通常是 -128 到 127
Android 音视频编码常用的是 RGB 与 YUV 两种编码,并且还会经常在两种编码之间进行转换,因此我们有必要对这两种编码有更细致的了解。
1.1 RGB 编码
RGB 编码最多可以表示出 256 × 256 × 256 = 16777216 种不同的色值,也就是我们常说的 1600 万色。使用三维坐标系采用光学加法混色的方式,可以构建出基于 RGB 模型的色彩空间:
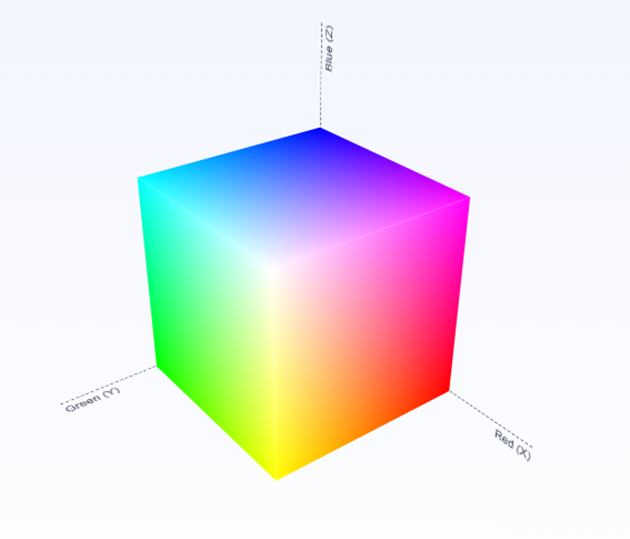
RGB 颜色模型存在一些问题:
- 因为在自然环境下获取的图像容易受自然光照、遮挡和阴影等情况的影响,即对亮度比较敏感,而 RGB 颜色空间的三个分量都与亮度密切相关,即只要亮度改变,三个分量都会随之相应地改变
- RGB 颜色空间是一种均匀性较差的颜色空间,人眼对于这三种颜色分量的敏感程度是不一样的,在单色中,人眼对红色最不敏感,蓝色最敏感,如果颜色的相似性直接用欧氏距离来度量,其结果与人眼视觉会有较大的偏差。对于某一种颜色,我们很难推测出较为精确的三个分量数值来表示
- 在视频领域如果使用 RGB 存储的话,视频数据会非常大。比如有一个 1080p 的视频,
1920 * 1080分辨率、帧率为 30 帧,如果使用 RGB 进行存储的话,仅仅一分钟的视频就能达到1920 * 1080 * 3 * 30 * 60 ≈ 10.4G。这明显是不现实的,所以我们需要对视频数据进行压缩
基于以上几点,我们需要一种数据相关性没那么强的颜色编码系统或色彩空间,而 YUV 正好就是这样。
1.2 YUV 编码
YUV(亮度、色度、色度)是另一种颜色编码系统,通常用于视频和图像处理领域,可以在保持图像质量的同时实现较高的压缩比。它将颜色信息分为亮度(Y)和色度(U、V)两个分量,其中亮度信息(Y 分量)被视为重要的部分,而色度信息(U、V 分量)可以以较低的分辨率进行采样,以减少数据量,提高图像和视频的压缩效率。
Y 其实就是我们常说的灰度值,是图片的总体轮廓,而 U 和 V 则用于描述色彩颜色和颜色饱和度。一张色彩艳丽的图片如果存储成 YUV 格式的话,Y 就是这张图的黑白照、UV 就是涂上颜色:

视频编码为何采用 YUV 格式
视频编码采用的是 YUV 格式,而不是 RGB,原因如下:
- 人眼对亮度更敏感:人眼对图像的亮度变化更敏感,而对色度变化的敏感性相对较低。因此,将图像分为亮度(Y)和色度(U、V)分量可以更有效地利用编码位率,并在保持较高图像质量的同时减少数据量
- 色度子采样:YUV 使用色度子采样的方式,即对色度分量进行降低采样。在 YUV 中,亮度分量(Y)的采样密度高于色度分量(U、V),这意味着色度分量的分辨率相对较低。由于人眼对色度信息的敏感度较低,对色度进行降采样可以在保持图像质量的同时减少数据量
- 视频压缩效果更好:采用 YUV 格式进行视频编码时,可以更好地利用视频中的空间相关性。颜色信息通常在相邻像素之间变化较小,因此对色度分量进行降采样不会对视觉感知产生明显影响,同时可以有效压缩视频数据
- 兼容性和传输效率:YUV 是广泛支持的视频格式,几乎所有的视频编码器和解码器都支持该格式。此外,许多视频传输和存储系统也支持 YUV 格式,因为它具有较高的兼容性和传输效率
对于相同分辨率的图片而言,YUV 占用的存储空间可以是 RGB 的一半。YUV 有多种采样方式,我们这里是以 YUV420、 2 * 2 的像素矩阵为例:
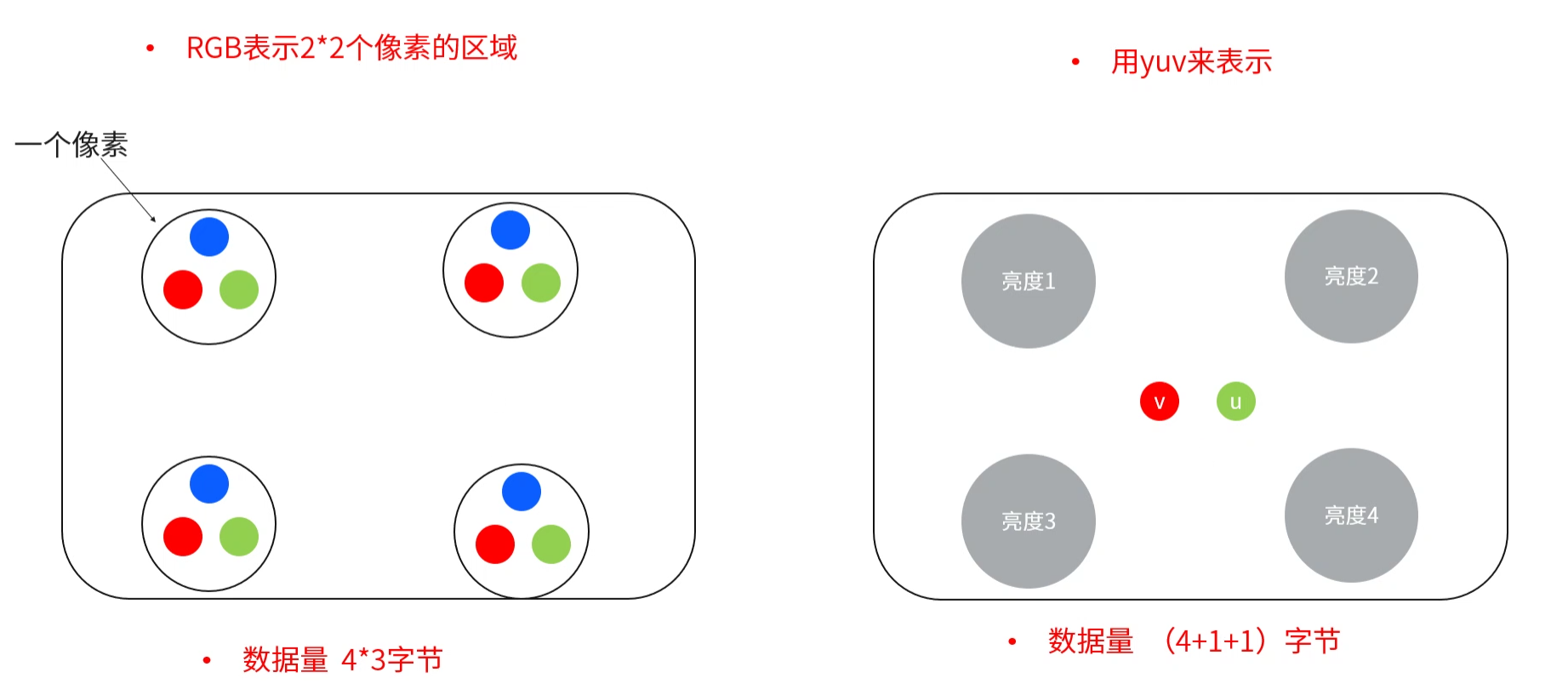
RGB 每个颜色通道需要用一个字节表示,每个像素点就需要占用 3 个字节,4 个像素点就需要 4 * 3 = 12 个字节。
YUV420 每个像素点都有一个字节表示亮度分量 Y,而 UV 分量每 4 个字节才有一组(即 U、V 数量分别为 Y 的 1/4),因此 4 个像素点占用 4 + 1 + 1 = 6 个字节。
YUV 格式分类
YUV 编码格式可以从如下角度进行分类:
- 色度采样方式:常见的有 YUV 444、YUV 422、YUV 420
- YUV 444:每个 Y 分量分别对应一个 U 分量和一个 V 分量。与 RGB 占用的大小一样,并没有节省存储空间
- YUV 422:每两个 Y 分量共用一个 U 分量和一个 V 分量。相比于 RGB 节省了三分之一的空间
- YUV 420:每四个 Y 分量共用一个 U 分量和一个 V 分量。相比于 RGB 节省了一半的空间,也是现在最常见的采样方式
- 存储方式:packed 打包方式与 planar 平面方式:
- packed:先连续存储所有的 Y 分量,然后依次交叉储存 U、V 分量
- planar:也会先连续存储所有的 Y 分量,但会先连续存储 U 分量的数据,再连续存储 V 分量的数据,或者先连续存储 V 分量的数据,再连续存储 U 分量的数据。将 YUV 分量分别存储到矩阵,每一个分量矩阵称为一个平面
上述两种方式结合,又会衍生出多种格式,以 YUV 420 采样方式、 6 * 6 的像素为例:
Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y
U U U U U U V V V V V V U V U V U V V U V U V U
V V V V V V U U U U U U U V U V U V V U V U V U
- I420 - - YV12 - - NV12 - - NV21 -
可以看到四种格式对 Y 分量的排列方式是一样的,区别在于 UV 分量的存放方式。前两种采用了 planar 存储方式,后两种采用了 packed 存储方式:
- 对于 I420,可以将占用的内存按比例分为 4:1:1,4 全部放 Y,第一个 1 全部放 U,第二个 1 全部放 V
- 对于 YV12,可以将占用的内存按比例分为 4:1:1,4 全部放 Y,第一个 1 全部放 V,第二个 1 全部放 U
- 对于 NV12,可以将内存按比例分为 4:2,4 全部放 Y,而 2 成对存放 UV,U 在 V 的前面
- 对于 NV21,可以将内存按比例分为 4:2,4 全部放 Y,而 2 成对存放 VU,V 在 U 的前面
了解 YUV 编码格式有助于我们实现视频编码。在直播推流 Demo 中,由于 Android 设备摄像头全部都采用 NV21 编码,而其他系统如 Windows 和 IOS 采用 I420 编码,所以在 Android 摄像头采集到 NV21 的图像数据之后,还需要转换成 I420 格式才可以推流到服务器。
1.3 RGB 与 YUV 转换
在音视频开发中,RGB 与 YUV 之间经常会发生转换(二者可以进行无损转换)。
通常 YUV 是摄像头采集到的视频格式(作为视频编解码的数据集),而 RGB 是显示在设备屏幕上的格式(屏幕渲染的数据集)。图像采集时需要将 RGB 数据转换成 YUV 数据保存,而播放视频时则需要将 YUV 数据转换成 RGB 在屏幕上渲染。
摄像头采集的图像可以直接采集成 YUV 数据,也可以采集成 RGB 数据再转换成 YUV:
- 摄像头可以直接输出 YUV 格式的图像数据,这意味着摄像头内部的图像传感器将图像直接转换为 YUV 格式。这种情况下,摄像头会提供原始的 YUV 数据,可以直接使用或进一步处理
- 然而,在其他情况下,摄像头可能会输出 RGB 格式的图像数据。在这种情况下,摄像头会将图像采集为 RGB 数据,然后通过图像处理器或芯片将 RGB 数据转换为 YUV 格式。这种转换通常是由摄像头硬件或驱动程序完成的
而将 YUV 转换成 RGB 数据的一个常用场景是在做音视频播放器,将视频帧解码出来放到 SurfaceView 上进行渲染前,可以使用 FFmpeg 提供的 SwsContext 转换上下文的 sws_scale() 实现转换:
// 转换上下文,前三个参数是源视频的宽高与像素格式,4~6 是目标视频的宽高与像素格式
SwsContext *swsContext = sws_getContext(
mAVCodecContext->width, mAVCodecContext->height, mAVCodecContext->pix_fmt,
mAVCodecContext->width, mAVCodecContext->height, AV_PIX_FMT_RGBA,
SWS_BILINEAR, nullptr, nullptr, nullptr);
// 执行 YUV -> RGBA 转换,转换后的数据保存在 dst_data 和 dst_lineSize 中
sws_scale(swsContext, avFrame->data, avFrame->linesize, 0,
mAVCodecContext->height, dst_data, dst_lineSize);
2、视频编码
2.1 为何编码
说起视频,我们很容易想到 mp4、flv、avi 等视频格式,但是这些格式都是经过视频编码后产生的压缩格式。那为什么要对原始视频进行编码呢?
因为原始视频文件太大了,1 分钟的原始 720p 视频文件可能在 2 ~ 4GB 之间。如果不进行编码,那我们的硬盘里估计也存不了几步电影。经过编码,75MB 的 RGBA 视频文件可以被压缩为 500KB 的 H.264 文件。
编码的目的,就是为了压缩。各种视频编码方式,都是为了让视频变得体积更小,有利于存储和传输。
2.2 如何编码
编码的核心思想就是去除冗余信息。压缩数据,或者说进行编码时,通常会从如下角度入手:
- 空间冗余:图像内部相邻像素之间存在较强的相关性多造成的冗余。比如相邻两帧有很多像素是重复的,那么可以考虑只保留一份重复数据
- 时间冗余:视频图像序列中的不同帧之间的相关性所造成的冗余。在相同像素的基础上,参考前后不同的部分计算出当前帧不同部分的内容
- 视觉冗余:是指人眼不能感知或不敏感的那部分图像信息。比如人类对亮度敏感,能分辨出深红色与浅红色,但是对色调不敏感,对红色偏一点橘红就不敏感,可以从像素值上进行压缩
- 信息熵(shāng)冗余:也称编码冗余,人们用于表达某一信息所需要的比特数总比理论上表示该信息所需要的最少比特数要大,它们之间的差距就是信息熵冗余,或称编码冗余。可以使用熵编码 —— 哈夫曼算法再次进行压缩
- 知识冗余:是指在有些图像中还包含与某些验证知识有关的信息
对于 Android 设备而言,摄像头采集到的原始视频格式为 YUV,麦克风采集到的原始音频数据格式为 PCM。
大致的录制与编码过程为:
- 采集原始数据:摄像头录制视频,得到原始的 YUV 格式数据;麦克风采集音频数据,得到原始的 PCM 数据
- 编码得到压缩数据:使用 H.264 或 H.265 对 YUV 进行编码,得到视频压缩数据;使用 AAC 编码器对 PCM 进行编码,得到音频压缩数据
- 封包得到视频文件:将音视频压缩数据封包,制成 mp4、flv 等压缩格式的视频文件
编码的基本思路如下:
- 在相邻几幅图像画面中,一般有差别的像素只有 10% 以内的点,亮度差值变化不超过 2%,而色度差值的变化只有1% 以内,所以对于一段变化不大图像画面,我们可以先编码出一个完整的图像帧 A
- 随后的 B 帧就不编码全部图像,只写入与 A 帧的差别,这样 B 帧的大小就只有完整帧的 1/10 甚至更小! B 帧之后的 C 帧如果变化不大,我们可以继续以参考 B 的方式编码 C 帧,这样循环下去
- 这段图像我们称为一个序列:序列就是有相同特点的一段数据,当某个图像与之前的图像变化很大,无法参考前面的帧来生成,那我们就结束上一个序列,开始下一段序列也就是对这个图像生成一个完整帧 A1,随后的图像就参考 A1生成,只写入与 A1 的差别内容
上述过程其实涉及了视频的 I 帧(完整编码的帧)、P 帧(参考之前的 I 帧生成的只包含差异部分的帧)、B 帧(参考前后的帧编码的帧)。其中与 I 帧相似程度极高达到 95% 以上的编码成 B 帧,相似程度 70% 的编码成 P 帧。下一小节详解这三种帧。
2.3 I 帧、P 帧与 B 帧
视频编码时需要设置 I 帧、P 帧与 B 帧的相关信息,它们的含义为:
- I 帧:帧内编码帧,关键帧,I 帧可以看作一个图像经过压缩之后的产物,可以单独解码出一个完整的图像(压缩率最低)
- P 帧:前向预测/参考编码帧,记录了本帧跟之前的一个关键帧或 P 帧的差别,解码时需要用之前缓存的画面叠加上本帧定义的差别,生成最终画面(压缩率比 I 帧高,比 B 帧低,压缩适中)
- B 帧:双向预测/参考编码帧,记录了本帧与前后帧的差别,解码需要参考前面一个 I 帧或者 P 帧,同时也需要后面的 P 帧才能解码出一张完整的图像(参考前后的预测得到的,压缩率是最高,但是耗时)。因此直播时 B 帧用的很少或者干脆不要 B 帧,因为直播要保证时效
设置 I 帧、P 帧与 B 帧是为了方便解码:
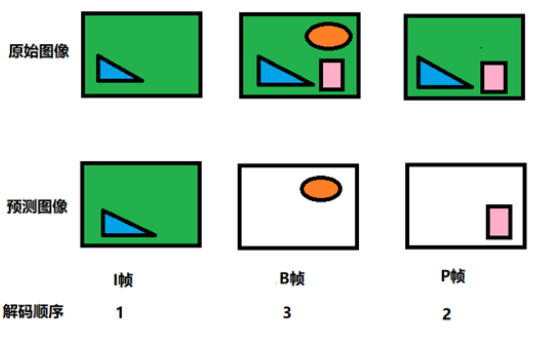
I 帧可以理解为一段场景中的第一帧,解码时一定是先解码出一个基准帧,后续的帧再在 I 帧的基础上填补有差别的部分。因此最先解码的是 I 帧。
B 帧要双向参考才能解码,因此在解码 B 帧之前,要先将 P 帧解码出来作为 B 帧后面的参考帧,因此 B 帧是最后被解码的。
I 帧只考虑本帧;P 帧记录的是与前一帧的差别;B 帧记录的是与前后两帧的差别,能节约更多的空间,视频文件小了,但是对解码来说比较麻烦。因为不仅要用之前的缓存画面,还要知道下一个 I 或者 P 的画面。对于不支持 B 帧解码的播放器容易卡顿。视频监控和直播等系统对画面流畅性要求较高,采用 I 帧、P 帧进行视频传输可以提高网络的适应能力,且能降低解码成本,所以现阶段视频直播都只采用 I 帧和 P 帧进行传输。
若干个 I、P、B 帧可以形成一个 GOP 序列:

前面提到过 P 帧与 I 帧的相似程度大概有 70%,如果低于这个比例就可以理解为场景变化较大,不能再使用这个 I 帧来编码,需要一个新的 I 帧。因此一个 I 帧引领的帧序列,即 GOP 就可以理解为一个场景。
2.4 H.264 简介
视频编码就是指通过特定的压缩技术,将某个视频格式文件转换成另一种视频格式文件的方式。
编码标准有两个:
- 国际电信联盟(ITU-T)的 H.26X 系列,常用的有 H.264、H.265,在这之前还有 H.261、H.263
- ISO 国际标准化组织的 MPEG 系列,如 MPEG1、MPEG2、MPEG4 AVC 等
从 H.264 开始,两个组织合作推出编码标准,只不过 ITU-T 将其称为 H.264,而 ISO 将其称为 MPEG4 AVC。H.264/MPEG4 AVC 标准的继任者是 H.265/HEVC,它被称为高效率视频编码(High Efficiency Video Coding)。H.265 在 H.264 的基础上加入了更多的算法,压缩率更高。
H.264 的分层结构:
- VCL:Video Coding Layer,视频编码层,负责高效地表示视频内容。VCL 数据就是编码的输出,表示被压缩编码后的视频数据序列
- NAL:Network Abstraction Layer,网络提取层,负责以网络所要求的恰当的方式对数据进行打包和传送(即格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传播)。属于传输层,不管在本地播放还是网络播放,都要通过这一层来传输
VCL 是编码压缩后的原始数据,在 VCL 数据封装到 NAL 单元之后才可以被传输或存储。
2.5 NALU
编码的目的是为了方便传输(文件传输或网络流传输),由于一帧的完整内容太大,我们并不能把一整帧传过去,否则对方等的花都要谢了。因此需要细分,需要更小的传输单元以保证更好的压缩性、容错性和实时性。
NAL 层数据的基本单位是 NALU,也称为 NAL 单元,如下图所示为 H.264 原始码流(又称为裸流),是由一个接一个的 NALU 组成的:

在每一个 NALU 的前面都有一个起始码作为分隔符以便接收端能够正确解析和处理 NALU 数据单元,起始码可以是 0x00000001 或者 0x000001:
- 0x00000001:表示 NALU 内有多个片
- 0x000001:表示 NALU 内只有一个片
而 NALU 内部可分为 NALU 头和 NALU 负载(RBSP 为负载的表现形式),其代码结构如图:
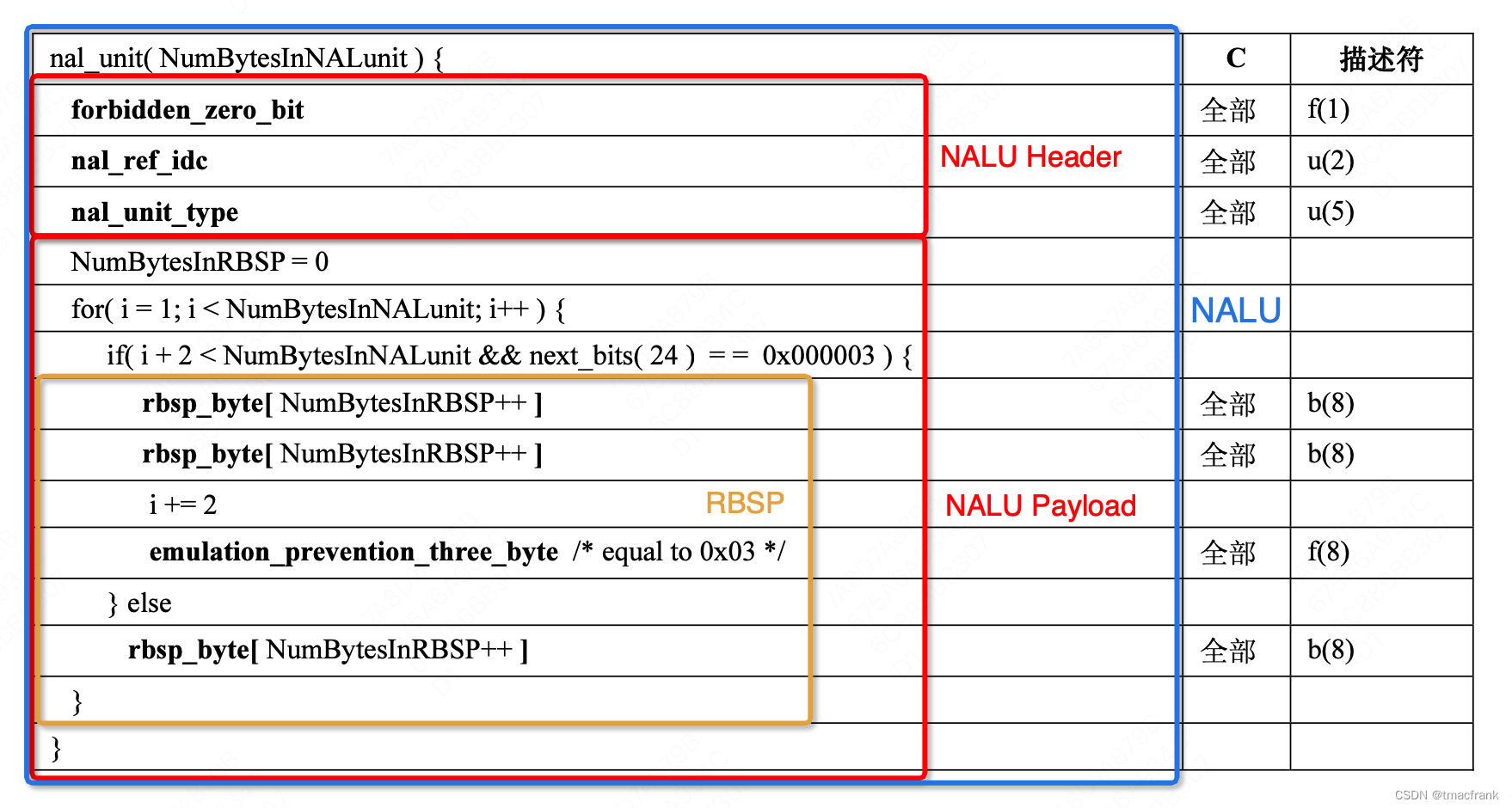
NALU 头
NALU 头仅有一个字节,包含如下三种信息:
- 禁止位(最高位):H.264 规定这一位必须为 0,否则意味着该帧不可用
- 重要性指示位(紧接的两位):值越大表示当前 NAL 越重要
- NALU 数据类型(低五位):负载数据类型,值为 7 时表示 SPS,8 表示 PPS,详情见下表

我们比较关注的是以下几个值:
- nal_unit_type = 5:表示这是一个 I 帧关键帧,此时整个 NALU 头的值为 0x65。播放器需要从 IDR 开始播放,编码时,发送 IDR 前需要发送 SPS 与 PPS
- nal_unit_type = 7 表示这是一个 SPS 序列参数集,此时整个 NALU 头的值为 0x67。包含了编码所用的 profile、level、图像宽高与颜色、deblock 滤波器等信息
- nal_unit_type = 8 表示这是一个 PPS 图像参数集,此时整个 NALU 头的值为 0x68。通常情况下,类似于 SPS
- 其他数值:P 帧或 B 帧等需要参考帧进行编码的帧
比如我们使用 010Editor 查看 H264 格式的文件:

可以看到图片中截取了三个 NALU 数据:
- 第一段起始码为 0x00000001,NAL Header 为 67,转换为二进制为 0110 0111,开头 0 是 H.264 的强制规定,接着 11 表示是最重要的帧,最后 5 位的十进制表示为 7,查表可知该 NALU 的数据类型为序列参数集 SPS
- 第二段起始码也是 0x00000001,NAL Header 为 68,也就是说高三位为 011,与第一段一样,只不过低 5 位值为 8,表示该 NALU 的数据类型为图像参数集 PPS
- 第三段起始码为 0x000001,表示该 NALU 中只有一帧,NAL Header 为 06,转换为二进制为 0000 0110,两位重要性指示位为 00,表示重要度最低,低五位十进制值为 6,表示 NALU 数据类型为辅助增强信息 SEI
NALU 负载
NALU 负载是视频编码中的数据单元,它是视频压缩标准(如H.264/AVC、H.265/HEVC)中的基本单元。NALU 负载包含了视频编码器生成的压缩数据,可以包括图像切片、参数集、帧头、码流数据等。NALU 负载通过网络进行传输,常用于视频流媒体、视频通信等应用中。
RBSP(Raw Byte Sequence Payload)是 NALU 负载的一种表示形式。RBSP 是指 NALU 负载中的原始字节序列,它包含 NALU 负载的所有数据,包括起始码、NALU 头、语法元素和填充字节等。RBSP 的目的是将 NALU 负载的数据按字节序列进行组织和表示,以便进行压缩和传输。
在视频编码过程中,视频编码器首先将原始视频帧进行压缩,并生成 NALU 负载。然后,这些 NALU 负载可以通过网络传输到解码器进行解码和播放。在传输过程中,通常会先将 NALU 负载转换为 RBSP 表示形式,然后再进行封装和传输。
如下图所示,一个视频当中有若干个帧,每一帧会被分割为若干个片,每一片中又包含若干个宏块(至少一个宏块,最多包含整个图像宏块,H.264 默认使用 16 × 16 大小的区域作为一个宏块,也可以划分成 8 × 8 大小),宏块则是若干个像素点组成的像素矩阵:
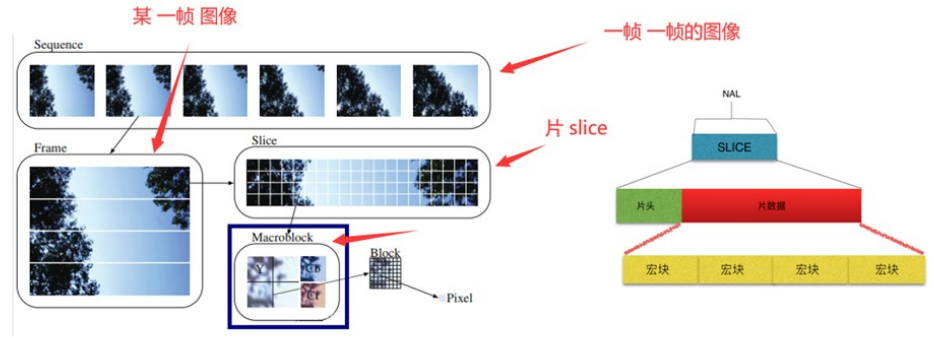
当一帧图像被编码时,它会被划分为多个 Slice,每个 Slice 包含了一部分图像数据和相关的编码信息。一个 NALU 可以包含一个或多个 Slice 以进行传输或存储。
3、视频解码
我们做播放器就是对压缩视频进行解码,然后将视频帧渲染到屏幕上。完整的音视频解码过程如下图:
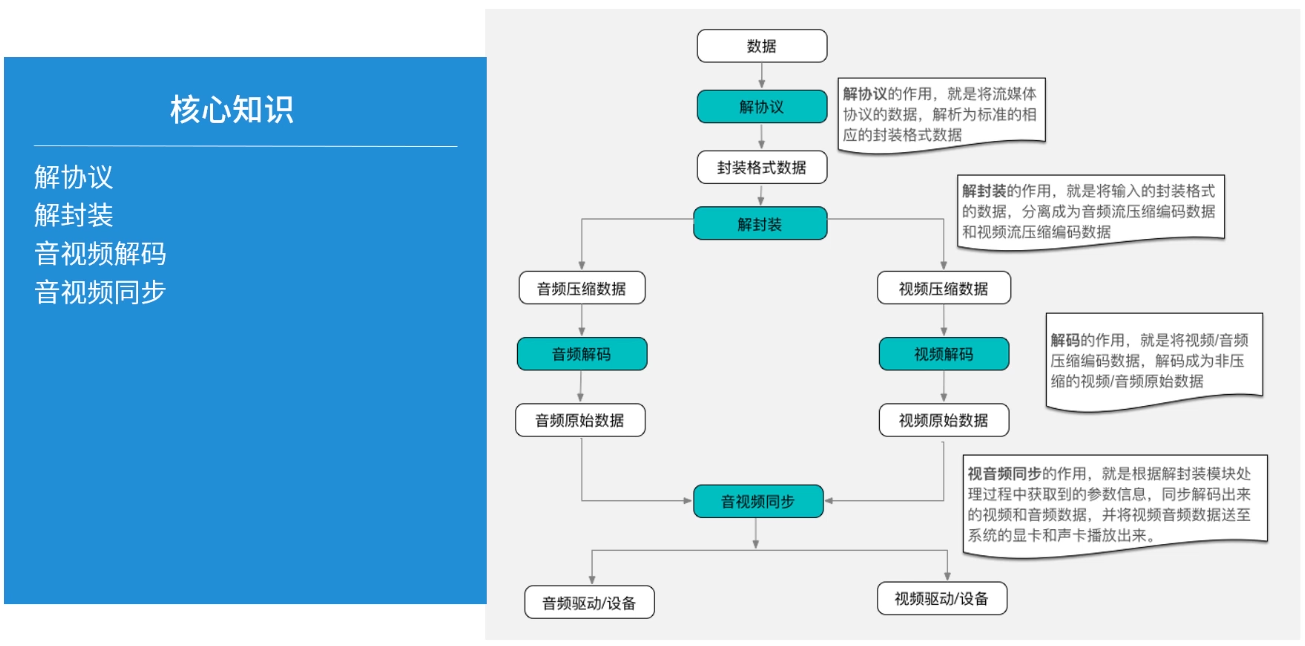
解协议会得到如下这些封装格式的视频文件,对其进行解封装分别得到音视频压缩数据:
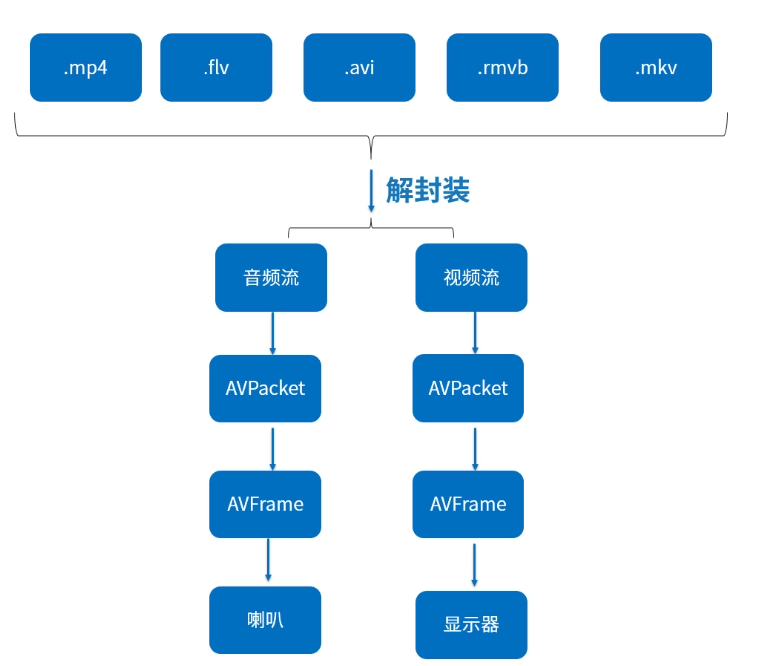
音视频流都是压缩格式数据,处理时需要先读取一帧数据到 AVPacket 中,然后解码为原始音视频数据放入 AVFrame,最后将原始数据转换成可播放的格式后交给播放设备播放(视频原始数据是 YUV 格式的,需要转换成 RGBA 格式后才能在 Android 的 SurfaceView 上显示,音频类似)。可以总结为如下步骤:
- 获取总上下文,根据总上下文可以打开视频文件
- 遍历流
- 获取解码参数,拿到解码器上下文
- 获取解码器
- 流中读取 AVPacket
- AVPacket 转换成 AVFrame
- 统一转换成可显示、可播放的格式
- 输出到相应设备
AVPacket 和 AVFrame 是 FFmpeg 提供的用于保存音视频数据的对象。
AVPacket 存储的是压缩(编码)后的音视频数据,而 AVFrame 存放的是解压(解码)后的音视频数据。
AVPacket 包括音频压缩数据,视频压缩数据和字幕压缩数据。它通常在解复用操作后存储压缩数据,然后作为输入传给解码器。或者由编码器输出然后传递给复用器。一个 AVPacket 通常只包含一个视频帧,但是可以存放几个音频帧。
在解码时,通常是通过 av_read_frame() 和 avcodec_send_packet() 得到压缩数据包 AVPacket,然后用 avcodec_receive_frame() 将 AVPacket 解码得到 AVFrame。
4、常用音频概念
在做音频编解码时,需要设置一些音频参数,因此我们需要先了解常用的音频概念:
- 音频:指人耳可以听到的声音频率,是在 20Hz-20kHz 之间的声波
- 奈奎斯特采样定理:采样频率必须至少是被采样信号最高频率的两倍,即 ts >=2 * f_max(f_max 为一个连续时间信号的最高频率),才能保证在进行采样和重构后能够完全还原原始信号,不会失真和混叠。很多音频的采样频率都是 44100Hz 就是遵循的这个定理
- 采样频率:即取样频率,指每秒钟取得声音样本的次数。采样频率越高,声音的质量也就越好,声音的还原也就越真实,但同时占用的资源就越多。
22050Hz 的采样频率是常用的,44100Hz 已是 CD 音质,超过 48000Hz 或 96000Hz 的采样对人耳已经没有意义。因为人耳的分辨率很有限,太高的频率并不能分辨出来。这和电影的每秒 24 帧图片的道理差不多。如果是双声道(stereo),采样就是双份的,文件也差不多要大一倍 - 采祥位数:即采样值或取样值(就是将采样样本幅度量化)。它是用来衡量声音波动变化的一个参数,也可以说是声卡的分辨率。它的数值越大,分辨率也就越高,所发出声音的能力越强。
每个采样数据记录的是振幅,采样精度取决于采样位数的大小:- 1 字节 8 位,只能记录 256 个数,也就是只能将振幅划分成 256 个等级
- 2 字节 16 位,可以细到 65536 个数,这已是 CD 标准了
- 4 字节 32 位,能把振幅细分到 4294967296 个等级,实属没必要
- 通道数:即声音的通道的数目。常有单声道和立体声之分,单声道的声音只能使用一个喇叭发声(有的也处理成两个喇叭输出同一个声道的声音),立体声可以使两个喇叭都发声(一般左右声道有分工),更能感受到空间效果,当然通道数还可以更多
- 帧:帧记录了一个声音单元,其长度为样本长度(采样位数)和通道数的乘积
- 周期:音频设备一次处理所需要的帧数,对于音频设备的数据访问以及音频数据的存储,都是以此为单位
- 交错模式:数字音频信号存储的方式。数据以连续帧的方式存放,即首先记录帧 1 的左声道样本和右声道样本,再开始帧 2 的记录…
- 非交错模式:首先记录的是一个周期内所有帧的左声道样本,再记录所有帧的右声道样本
- 比特率:每秒的传输速率(也叫位速),如 705.6kbps 或 705600bps,其中 b 是 bit,ps 是每秒的意思,表示每秒 705600bit 的容量
- 音频编码:直接采用 16 进制保存的是 pcm 格式,非常大,需要通过编码方式减小其所占用的空间,如 aac